
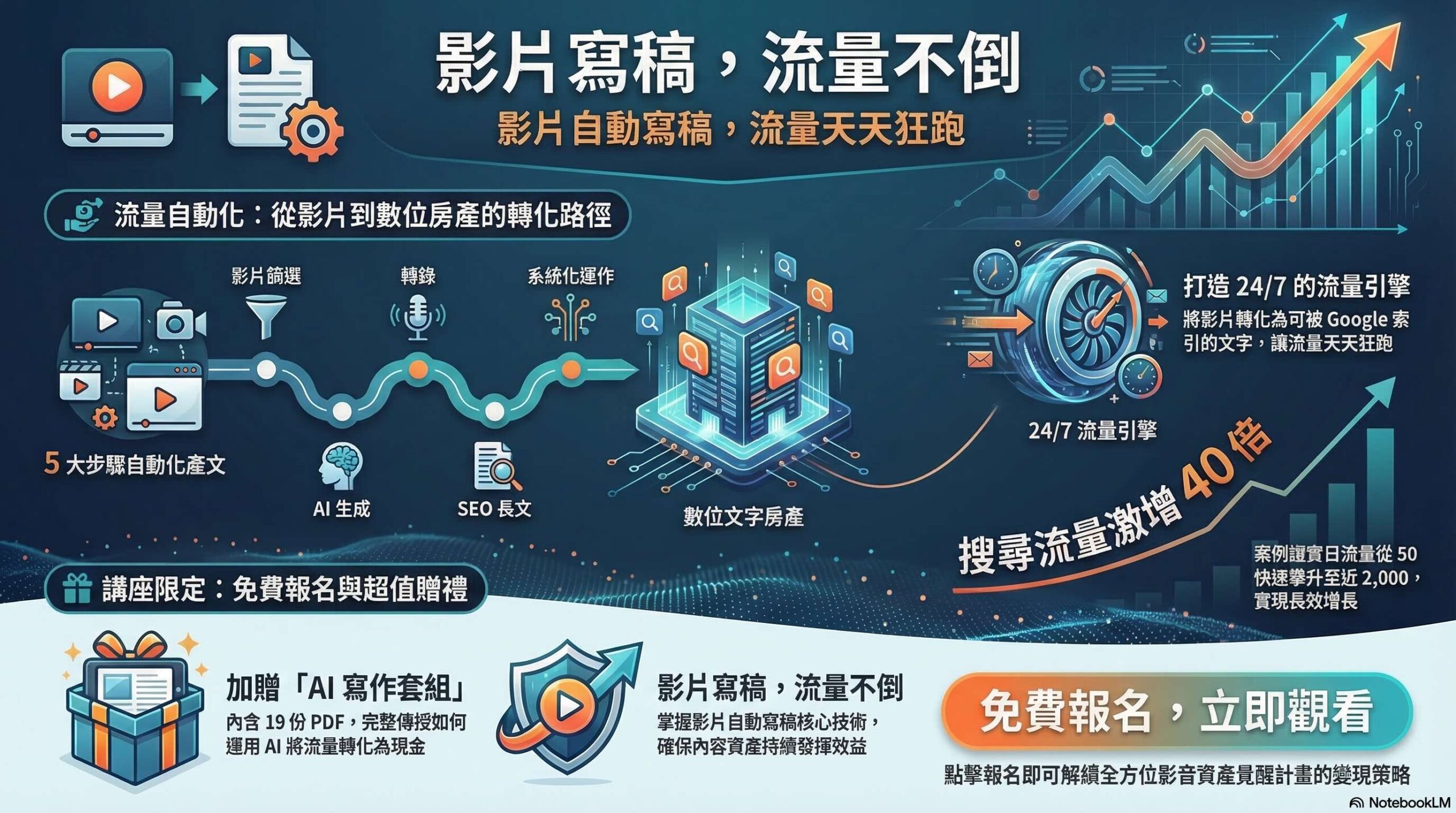
在一個陽光明媚的早晨,台北的一位年輕工程師小李正在為他的深度學習專案煩惱。他發現,模型的表現不如預期,數據的複雜性讓他感到無從下手。就在他準備放棄的時候,他的導師告訴他一個關鍵的秘密:激活函數。這個簡單的概念,卻能為他的模型注入生命,讓它能夠學習和適應。
激活函數是神經網絡中不可或缺的一部分,它決定了每個神經元的輸出。常見的激活函數包括Sigmoid、ReLU(修正線性單元)、Tanh等。每種函數都有其獨特的特性和適用場景,選擇合適的激活函數能顯著提升模型的性能。例如,ReLU在處理大規模數據時表現優異,而Tanh則在需要平衡輸出時更具優勢。
了解激活函數的多樣性,將使你在深度學習的道路上走得更遠。讓我們一起探索這些激活函數的奧秘,激活你的模型,開啟無限可能的未來!
文章目錄
深入淺出:台灣AI開發者必備的激活函數基礎知?
各位鄉親父老,大家好!身為一個在台灣打滾多年的 AI 程式開發者,我深深體會到,想要在 AI 領域闖出一片天,除了要有紮實的程式基礎,對數學的理解更是不可或缺。還記得我剛開始接觸 AI 時,就被各種數學公式搞得暈頭轉向。尤其是那些看似簡單,卻又變化多端的「激活函數」,更是讓我吃了不少苦頭。那時候,我常常熬夜苦讀,翻遍了各種書籍和網路資源,才慢慢摸索出一些門道。現在回想起來,那段經歷雖然辛苦,卻也讓我對激活函數有了更深刻的理解。
那麼,究竟有哪些激活函數是我們在台灣 AI 發展中不可或缺的呢?讓我來為大家揭曉幾個重要的:
-
Sigmoid 函數:
它的輸出範圍在 0 到 1 之間,常被用於二元分類問題。想像一下,你正在開發一個辨識台灣水果的 AI 模型,Sigmoid 函數就能幫助你判斷輸入的圖片是鳳梨還是芒果。
-
ReLU (Rectified Linear Unit) 函數:
它是目前最受歡迎的激活函數之一,計算速度快,能有效解決梯度消失的問題。在台灣,許多 AI 團隊都使用 ReLU 來訓練他們的深度學習模型,例如影像辨識、自然語言處理等等。
-
Tanh (Hyperbolic Tangent) 函數:
它的輸出範圍在 -1 到 1 之間,與 Sigmoid 函數類似,但能提供更強的梯度。
-
Softmax 函數:
它是多分類問題的利器,能將多個數值轉換成機率分佈。例如,在開發一個辨識台灣不同車種的 AI 模型時,softmax 函數就能幫助你判斷輸入的圖片是機車、汽車還是腳踏車。
這些激活函數各有優缺點,選擇哪一個取決於你的具體應用場景。根據台灣人工智慧學校的資料顯示,ReLU 和其變種函數在台灣的 AI 領域應用最廣泛。而根據國立台灣大學電機工程學系的相關研究,Softmax 函數在自然語言處理領域的表現也相當出色。
總之,掌握這些激活函數的特性,並善用它們,就能為你的 AI 專案打下堅實的基礎。希望我的經驗分享,能幫助到更多在台灣努力的 AI 開發者們!
精準解析:針對台灣應用場景的激活函數選擇策略
身為一個在台灣科技業打滾多年的老兵,我對激活函數的選擇,有著深刻的體會。記得當年,我剛從台大電機系畢業,滿懷熱情地投入AI領域。那時,我們團隊面臨一個棘手的問題:如何讓我們的智慧醫療影像分析系統,更精準地辨識台灣常見的肺部疾病?我們嘗試了各種激活函數,從最基本的Sigmoid和Tanh,到後來流行的ReLU。每一次的嘗試,都像是一場實驗,數據的起伏,模型的表現,都牽動著我們的心。最終,我們發現,針對台灣醫療影像的特點,ReLU及其變種,例如Leaky ReLU,在處理影像的細微差異上,表現更為出色。這段經歷讓我明白,激活函數的選擇,絕非一蹴可幾,而是需要根據實際應用場景,不斷嘗試和調整。
那麼,在台灣的應用場景中,我們該如何選擇激活函數呢?首先,我們要了解不同激活函數的特性。
-
Sigmoid 和 Tanh:
這些函數的輸出值介於0到1或-1到1之間,適合用於輸出需要被標準化的情況,例如機率預測。然而,它們容易出現梯度消失的問題,尤其是在深層神經網路中。
-
ReLU:
ReLU的計算速度快,且能有效解決梯度消失問題。在台灣的許多應用中,例如臉部辨識、語音辨識等,ReLU都是一個不錯的選擇。
-
Leaky ReLU 和 Parametric relu:
這些是ReLU的變種,它們在輸入為負數時,會給予一個小的斜率,避免了ReLU的”死亡”問題,進一步提升了模型的表現。
-
ELU 和 SELU:
這些函數在輸入為負數時,輸出值會趨近於負飽和,有助於穩定訓練過程,尤其是在處理影像和文字資料時。
為了確保資訊的可靠性,我們可以參考一些權威的資料來源。例如,台灣人工智慧學校的課程內容,經常會深入淺出地講解各種激活函數的原理和應用。此外,像是國立台灣大學電機資訊學院的相關研究論文,也提供了許多關於激活函數在不同應用場景下的實驗結果和分析。這些資料,都為我們提供了寶貴的參考,幫助我們做出更明智的選擇。另外,像是科技部所支持的AI研究計畫,也經常會發表最新的研究成果,這些都是我們了解最新技術趨勢的重要管道。
總之,在台灣的AI應用中,激活函數的選擇,需要根據具體的任務和資料特性來決定。沒有一個函數是萬能的,只有最適合的。透過不斷的實驗、學習和參考權威資料,我們才能找到最優的解決方案,為台灣的AI發展貢獻一份力量。記住,每一次的嘗試,都是一次成長的機會。讓我們一起,在AI的道路上,不斷探索,不斷前進!
常見問答
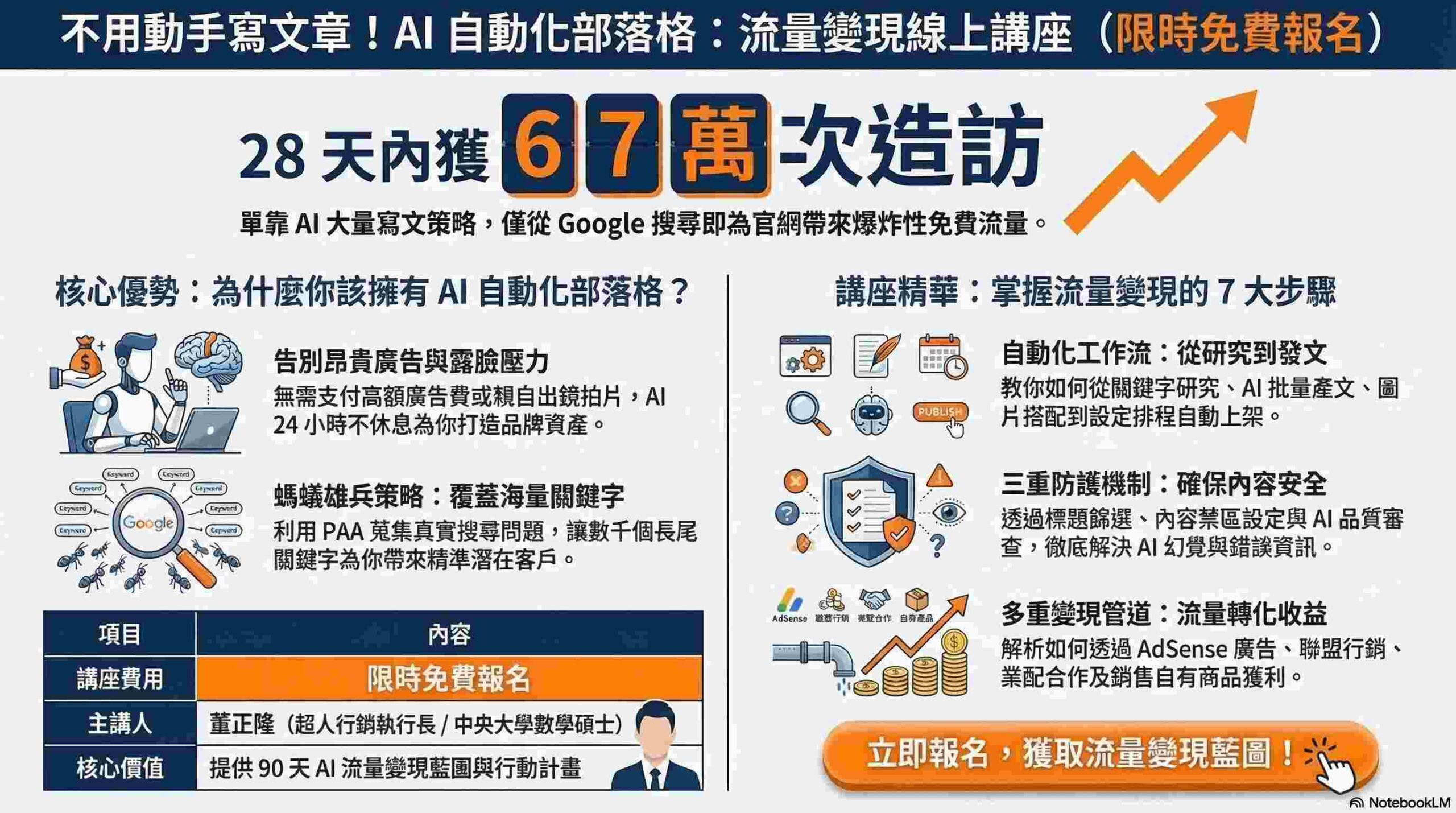
激活函數有哪些?
作為一位經驗豐富的內容撰寫者,我將以清晰、簡潔的方式,為您解答關於激活函數的常見問題,助您深入理解這個重要的機器學習概念。
-
激活函數是什麼?為什麼重要?
激活函數是神經網路中的關鍵組件,它引入了非線性,使得神經網路能夠學習複雜的模式。簡單來說,它就像一個「閘門」,決定了神經元是否應該被「激活」,也就是是否將其輸出傳遞到下一層。沒有激活函數,神經網路只能執行線性變換,無法解決現實世界中許多非線性問題。在台灣,隨著AI技術的蓬勃發展,理解激活函數的重要性至關重要,它影響著模型學習的效率和準確性。
-
有哪些常見的激活函數?
常見的激活函數包括:
-
Sigmoid:
將輸入值壓縮到0到1之間,常用於二元分類問題。
-
Tanh:
將輸入值壓縮到-1到1之間,與Sigmoid類似,但輸出以0為中心。
-
ReLU (Rectified Linear Unit):
如果輸入為正,則輸出輸入值;如果輸入為負,則輸出0。ReLU是目前最常用的激活函數之一,因其計算效率高。
-
Leaky ReLU:
ReLU的變體,當輸入為負時,輸出一個很小的正數,避免了ReLU的「死亡神經元」問題。
-
Softmax:
常用於多類別分類問題,將輸出轉換為概率分佈。
選擇哪個激活函數取決於具體的任務和數據集。在台灣,許多研究團隊和企業都在探索不同激活函數的組合,以提升模型的性能。
-
-
如何選擇合適的激活函數?
選擇激活函數時,需要考慮以下因素:
-
任務類型:
二元分類、多類別分類、回歸等。
-
數據集的特性:
數據的範圍、分佈等。
-
模型的架構:
不同的層可能需要不同的激活函數。
-
梯度消失問題:
某些激活函數更容易導致梯度消失,影響模型的訓練。
通常,ReLU及其變體是首選,但具體情況需要通過實驗來驗證。在台灣,許多AI工程師會根據實際情況,結合經驗和實驗結果,來選擇最適合的激活函數。
-
-
激活函數的未來發展趨勢是什麼?
激活函數的研究仍在不斷發展,未來趨勢包括:
-
自適應激活函數:
根據數據和模型自動調整的激活函數。
-
新型激活函數:
旨在解決梯度消失、加速訓練的新型激活函數。
-
結合不同激活函數:
在同一模型中使用多種激活函數,以獲得更好的性能。
隨著AI技術的進步,激活函數的研究將持續推動神經網路的發展,為台灣的AI應用帶來更多可能性。
-
重點精華
總之,理解並善用激活函數,是建構高效能 AI 模型不可或缺的一環。從Sigmoid到ReLU,選擇最適合的函數,能有效提升模型表現,為您的 AI 專案注入無限可能! 本文由AI輔助創作,我們不定期會人工審核內容,以確保其真實性。這些文章的目的在於提供給讀者專業、實用且有價值的資訊,如果你發現文章內容有誤,歡迎來信告知,我們會立即修正。

中央大學數學碩士,董老師從2011年開始網路創業,教導網路行銷,並從2023年起專注AI領域,特別是AI輔助創作。本網站所刊載之文章內容由人工智慧(AI)技術自動生成,僅供參考與學習用途。雖我們盡力審核資訊正確性,但無法保證內容的完整性、準確性或即時性且不構成法律、醫療或財務建議。若您發現本網站有任何錯誤、過時或具爭議之資訊,歡迎透過下列聯絡方式告知,我們將儘速審核並處理。如果你發現文章內容有誤:點擊這裡舉報。一旦修正成功,每篇文章我們將獎勵100元消費點數給您。如果AI文章內容將貴公司的資訊寫錯,文章下架請求,敬請來信(商務合作、客座文章、站內廣告與業配文亦同):[email protected]


