
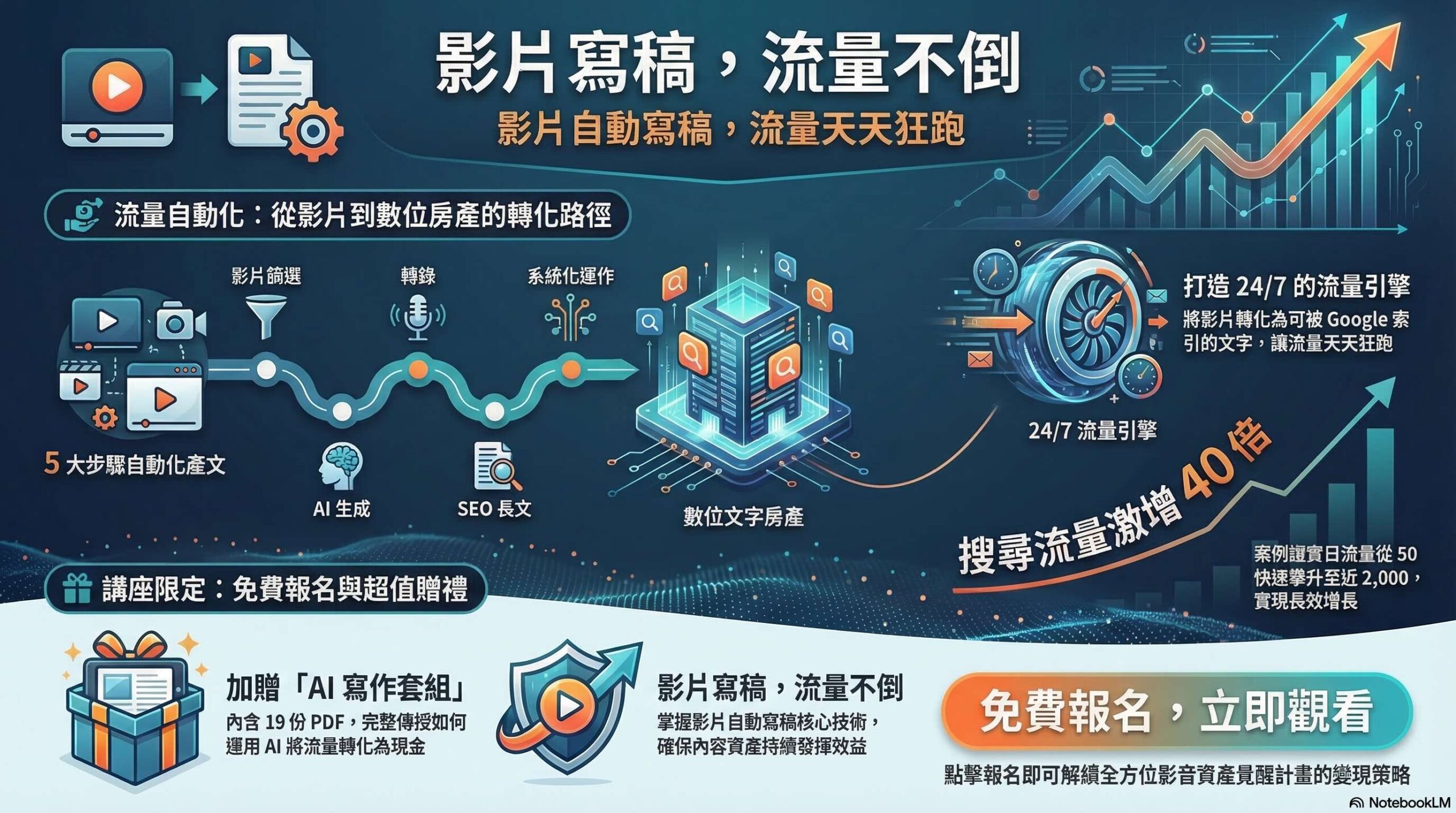
在台灣的科技界,人工智慧的發展如火如荼,許多人對於最新的AI模型充滿好奇。想像一下,您正在參加一場科技論壇,會議上有一位專家提到GPT-3模型的參數量級,讓在場的每一位聽眾都瞠目結舌。這個模型擁有1750億個參數,這不僅是數字的堆砌,更是智慧的結晶。這些參數使得GPT-3能夠理解和生成自然語言,從而在各種應用中展現出驚人的表現。
這樣的技術不僅改變了我們與機器互動的方式,也為企業帶來了無限的商機。無論是客服自動化、內容生成,還是數據分析,GPT-3的強大能力都能助力台灣企業在全球市場中脫穎而出。因此,了解GPT-3的參數量級,不僅是對科技的認識,更是把握未來趨勢的關鍵。讓我們一起探索這個充滿潛力的領域,迎接人工智慧帶來的無限可能。
文章目錄
解密 GPT-3:模型參數量級的驚人規模與影響
身為一個在台灣科技圈打滾多年的老鳥,我對 GPT-3 的震撼,至今仍記憶猶新。記得那時,我還在忙著處理公司網站的 SEO 優化,每天埋首於關鍵字分析、內容撰寫。突然間,GPT-3 橫空出世,它不僅能寫出流暢的文章,甚至能模仿不同的文風,這對我們這些內容創作者來說,簡直是場噩夢,但也同時是個令人興奮的機會。我親自試用,輸入幾個簡單的指令,它就能產出符合需求的文案,效率之高,令人咋舌。那時,我才真正意識到,AI 時代已經來臨,而我們必須擁抱改變。
那麼,這個讓全球科技界為之瘋狂的 GPT-3,它的模型參數量級究竟有多驚人? 簡單來說,它擁有數十億個參數,這是一個難以想像的數字。 想像一下,每個參數就像是大腦中的一個神經元,而 GPT-3 就像是一個擁有數十億個神經元的大腦。 根據 OpenAI 的官方資料,GPT-3 的模型參數量級約為 1750 億個。 這樣的規模,讓它能夠學習和理解大量的文本數據,進而產生令人印象深刻的語言能力。 相比之下,早期的 AI 模型,其參數量級可能只有數百萬甚至數十萬個,兩者之間的差距,就好比是從石器時代跨越到太空時代。
這種龐大的參數量級,對 GPT-3 的影響是深遠的。 首先,它賦予了 GPT-3 强大的泛化能力,也就是說,它能夠在未經訓練的任務上,也能表現出色。 其次,它讓 GPT-3 能夠理解更複雜的語言結構和語義,從而產生更自然、更流畅的文本。 此外,它也使得 GPT-3 能夠執行更廣泛的任務,例如翻譯、寫作、程式碼生成等等。 當然,如此龐大的模型也帶來了挑戰,例如訓練成本高昂、計算資源需求巨大等等。 但不可否認的是,GPT-3 的出現,極大地推動了自然語言處理技術的發展,也為我們開啟了 AI 應用的新篇章。
為了讓大家更了解這個數字的意義,我來舉幾個例子:
- 台灣人口: 台灣總人口約為 2300 萬人,GPT-3 的參數量級是台灣人口的數倍。
- 台積電市值: 台積電是台灣的驕傲,市值曾一度突破 7000 億美元,但 GPT-3 的模型訓練成本也相當可觀。
- 台北 101 大樓: 台北 101 大樓是台灣的標誌性建築,但 GPT-3 的複雜程度遠超於此。
這些例子,希望能幫助大家更直觀地理解 GPT-3 的參數量級,以及它所帶來的巨大影響。 參考資料來源:OpenAI 官方網站、Google AI 相關研究論文。
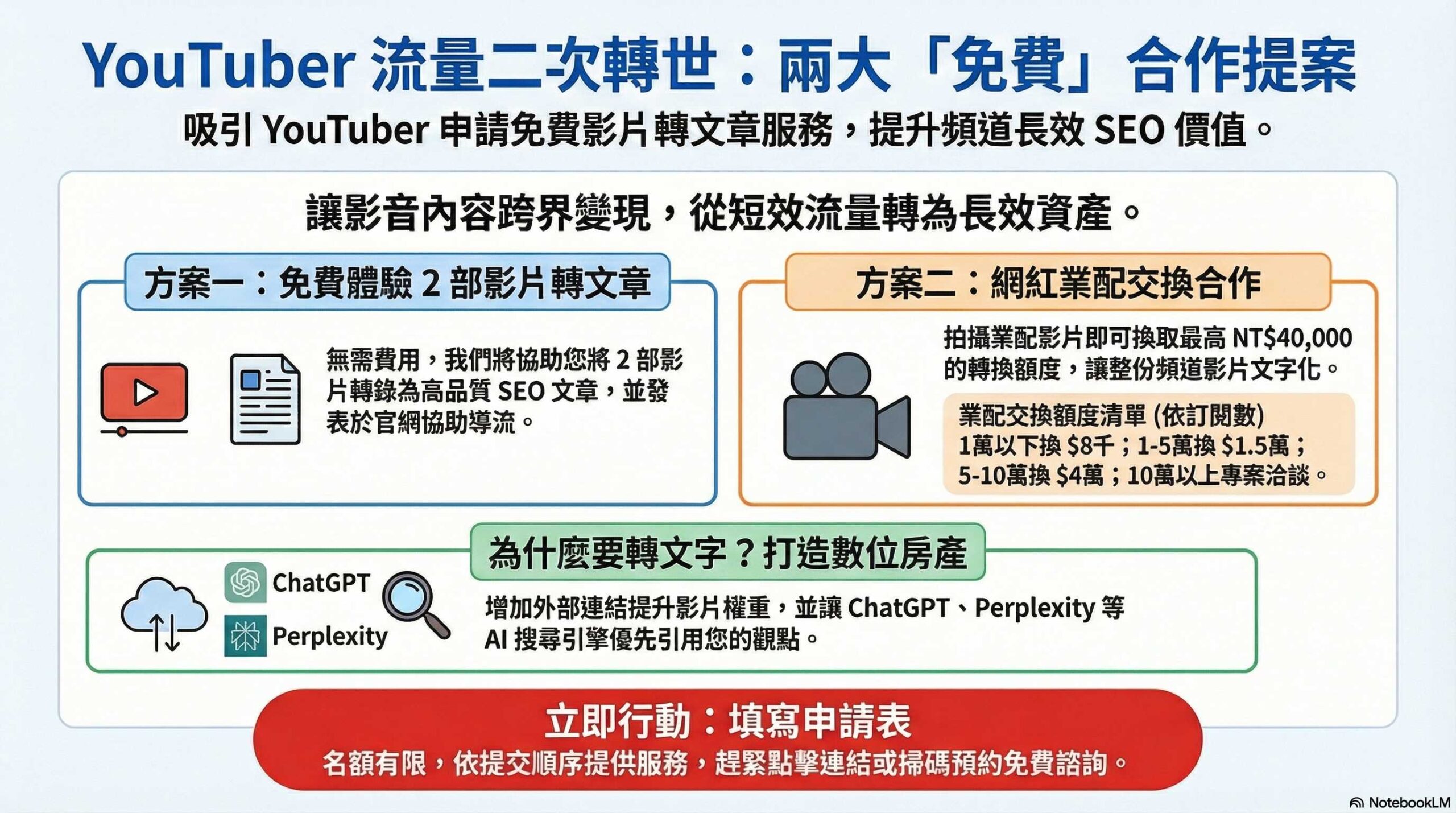
深入剖析 GPT-3 參數量級:技術細節、挑戰與未來展望
身為一個在台灣科技圈打滾多年的老屁股,我對 AI 的熱情可說是與日俱增。還記得幾年前,GPT-3 橫空出世時,簡直驚為天人!它那種能寫文章、能對話、甚至能寫程式碼的能力,徹底顛覆了我們對 AI 的想像。當時,網路上各種關於 GPT-3 的討論沸沸揚揚,而其中最引人入勝的,莫過於它那龐大的參數量級。 記得那時候,我還特地跑去參加了一場在台北舉辦的 AI 研討會,聽了幾位業界大老的分享,才對 GPT-3 的技術細節有了更深入的了解。那種感覺,就像是親眼見證了一場科技奇蹟的誕生,令人興奮不已。
那麼,究竟 GPT-3 的參數量級有多大呢? 根據 OpenAI 官方的說法,GPT-3 擁有 **1750 億個參數**。 什麼是參數? 簡單來說,參數就像是 AI 模型的「知識儲備」,模型透過學習大量的資料,調整這些參數,來提升它的語言理解和生成能力。 想像一下,這 1750 億個參數,就像是無數個微小的「知識點」,組成了 GPT-3 龐大的知識庫。 這樣的規模,遠遠超過了當時其他的 AI 模型,也讓 GPT-3 在各種任務上展現出驚人的表現。
當然,如此龐大的參數量級,也帶來了許多挑戰。 首先,訓練 GPT-3 需要耗費大量的運算資源,包括:
- 大量的 GPU 算力
- 巨額的電費支出
- 長時間的訓練時間
其次,如此複雜的模型也更容易受到「過擬合」的影響,也就是模型過度學習訓練資料,導致在新的資料上表現不佳。 此外,GPT-3 的可解釋性也相對較低,我們很難完全理解它做出決策的過程。 這些挑戰,都促使研究人員不斷探索新的技術,例如:模型壓縮、更高效的訓練方法,以及更易於理解的模型架構。
展望未來,AI 模型的發展趨勢,無疑是朝著更大、更強的方向邁進。 雖然 GPT-3 已經非常強大,但它仍然存在一些局限性,例如:缺乏常識、容易產生偏見等等。 然而,隨著技術的進步,我們可以預見,未來將會出現更多更強大的 AI 模型,它們將在各個領域發揮更大的作用。 根據台灣人工智慧學校的資料,台灣在 AI 領域的發展潛力巨大,政府也積極推動相關產業的發展。 相信在不久的將來,我們就能看到更多令人驚豔的 AI 應用,為我們的生活帶來更多便利和驚喜。
常見問答
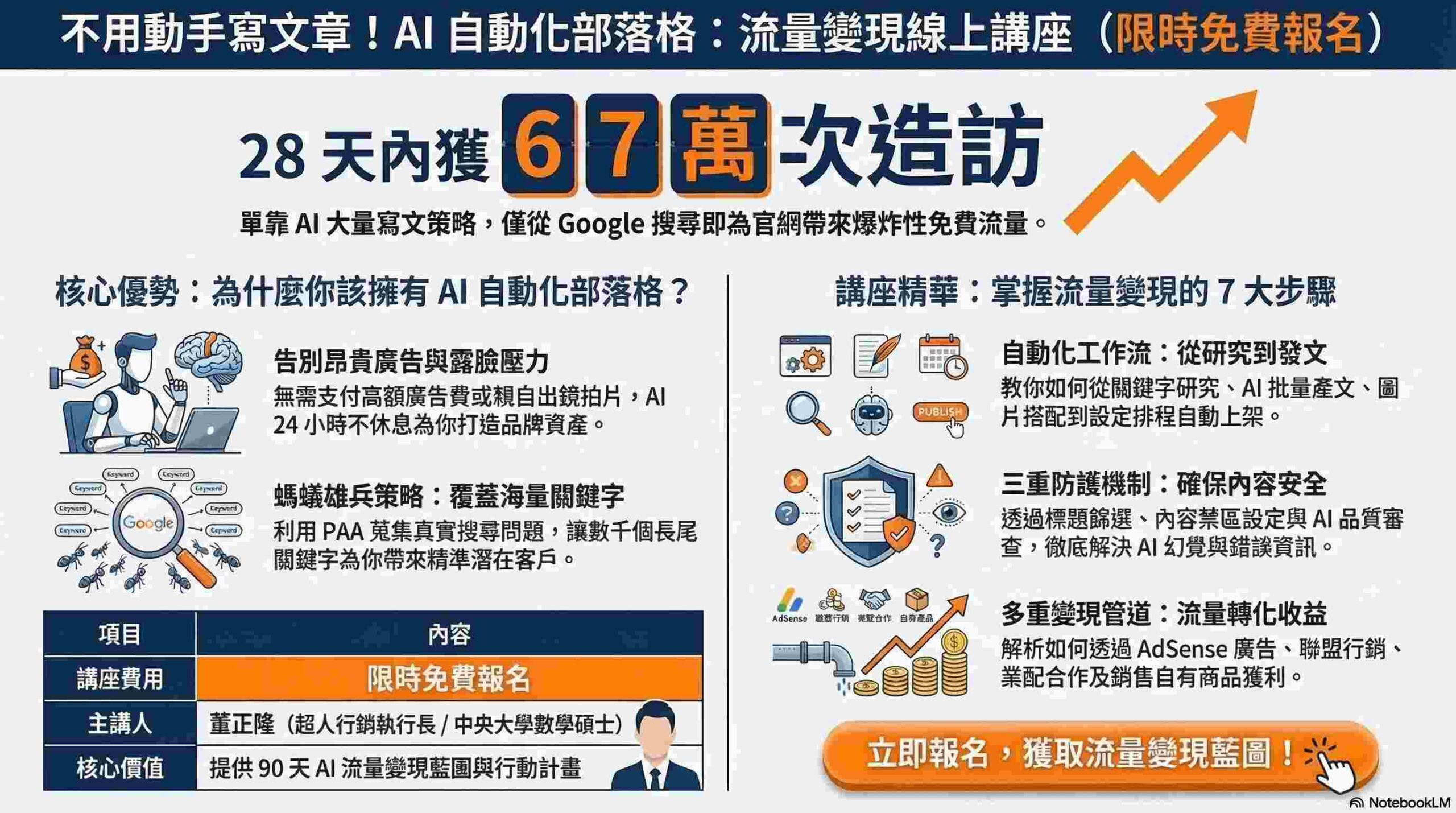
關於 GPT-3 模型參數量級的常見問題
作為一位內容撰寫者,我理解您對 GPT-3 模型的好奇。以下針對常見問題,提供清晰且具說服力的解答:
-
請問 GPT-3 模型的參數量級約為多少?
GPT-3 模型的參數量級非常龐大,大約有 1750 億個參數。這意味著它在訓練過程中學習了大量的資訊,使其能夠執行各種複雜的自然語言處理任務。
-
這麼多參數意味著什麼?
龐大的參數數量賦予 GPT-3 强大的能力,例如:
- 生成流暢且自然的文本。
- 理解並回應各種提問。
- 執行翻譯、摘要、程式碼生成等任務。
-
GPT-3 的參數量級與其他模型相比如何?
GPT-3 的參數量級遠遠超過了之前的自然語言處理模型。這使得它在許多任務上的表現都優於以往的模型,例如:
- 更準確的文本生成。
- 更強大的上下文理解能力。
-
了解參數量級對使用者有什麼幫助?
了解 GPT-3 的參數量級,有助於您:
- 理解其强大的功能。
- 預期其可能的應用範圍。
- 評估其在特定任務上的潛力。
重點精華
總之,GPT-3 模型的參數量級,著實令人驚嘆。理解這龐大數字,能幫助我們更深入地認識 AI 發展。未來,持續關注 AI 領域,台灣也能站穩腳步,掌握科技浪潮,開創無限可能。 本文由AI輔助創作,我們不定期會人工審核內容,以確保其真實性。這些文章的目的在於提供給讀者專業、實用且有價值的資訊,如果你發現文章內容有誤,歡迎來信告知,我們會立即修正。

中央大學數學碩士,董老師從2011年開始網路創業,教導網路行銷,並從2023年起專注AI領域,特別是AI輔助創作。本網站所刊載之文章內容由人工智慧(AI)技術自動生成,僅供參考與學習用途。雖我們盡力審核資訊正確性,但無法保證內容的完整性、準確性或即時性且不構成法律、醫療或財務建議。若您發現本網站有任何錯誤、過時或具爭議之資訊,歡迎透過下列聯絡方式告知,我們將儘速審核並處理。如果你發現文章內容有誤:點擊這裡舉報。一旦修正成功,每篇文章我們將獎勵100元消費點數給您。如果AI文章內容將貴公司的資訊寫錯,文章下架請求,敬請來信(商務合作、客座文章、站內廣告與業配文亦同):[email protected]
